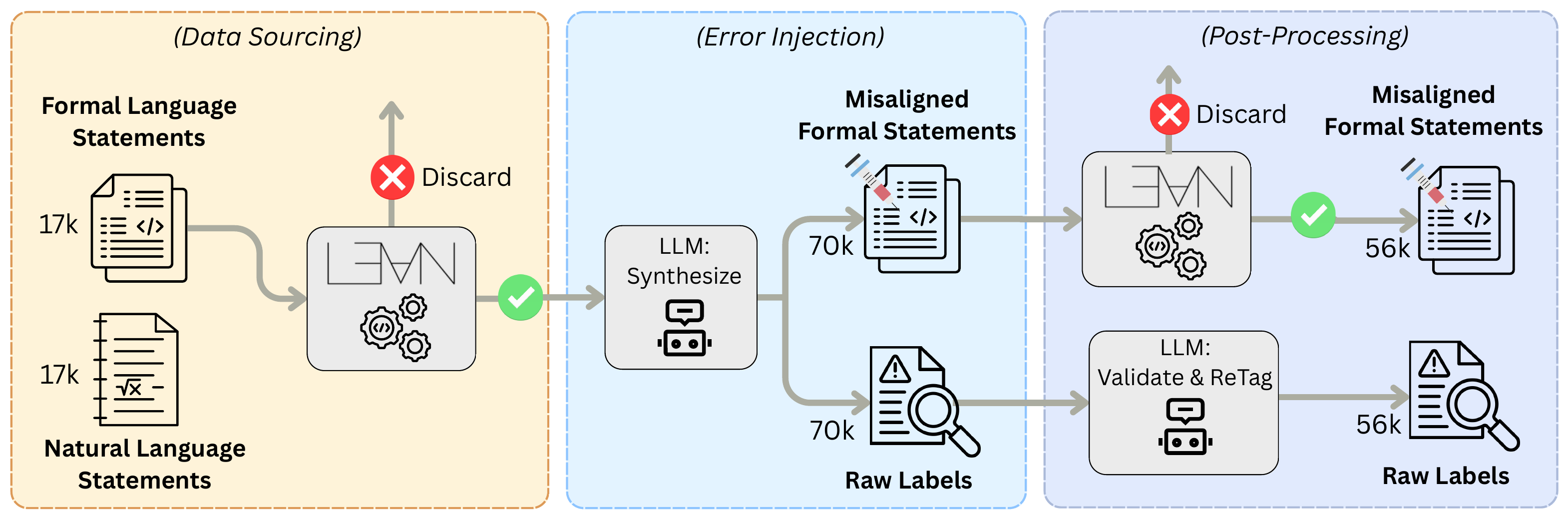
We release FormalRx-Test on Hugging Face: 7,030 natural-language / Lean 4 statement pairs annotated under the SCI Error Taxonomy. Each sample carries a natural-language problem, a candidate Lean 4 formalization, and a Lean header required to type-check the candidate.
Heads up. Inputs only are released for now. Ground-truth diagnoses stay withheld until the
ICML 2026 AI for Math Workshop & Challenge 1 closes (June 15, AoE). The fully labeled split will accompany the paper after the challenge ends.
Schema
Each sample is a JSON object:
{
"idx": "formalrx_1",
"header": "import Mathlib\nopen Real Set",
"informal_statement": "...natural language problem...",
"formal_statement": "theorem ... := by sorry",
"diagnosis": {
"aligned": "Aligned" | "Misaligned",
"error_type": "<one of 28 SCI categories>" | "N/A",
"error_location": "<minimal code snippet>" | "N/A",
"corrected_statement": "<complete corrected Lean 4 statement>" | "N/A"
}
}